

Dozens of big brands have blocked GPTBot, OpenAI’s new web crawler
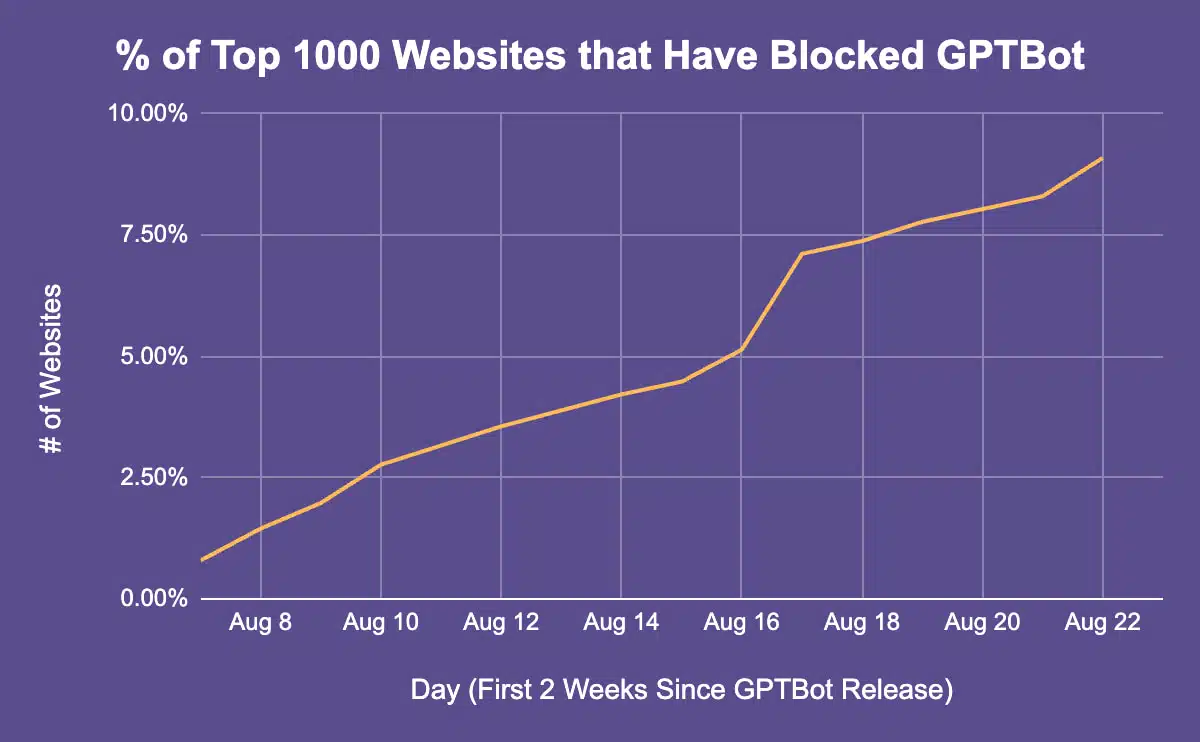
At least 69 of the most popular websites in the world have blocked GPTBot, the new web crawler OpenAI introduced Aug. 7, according to a new analysis.
And the percentage of sites is increasing, according to a new analysis by AI content and plagiarism service Originality.ai.
Why we care. To block or not to block ChatGPT? That has been the big question for many SEOs. Clearly, several popular websites have already blocked GPTBot, presumably because they don’t want OpenAI scraping their data to help train its models – at least not without compensation.
By the numbers. The 15 most popular sites blocking ChatGPT, according to the analysis, are:
- amazon.com
- quora.com
- nytimes.com
- shutterstock.com
- wikihow.com
- cnn.com
- foursquare.com
- healthline.com
- scribd.com
- businessinsider.com
- reuters.com
- medicalnewstoday.com
- goodhousekeeping.co
- amazon.co.uk
- tumblr.com
But. Even though many sites are blocking GPTBot, they are not blocking CCbot, Common Crawl’s web crawler. Part of the training data used by OpenAI, Google and others comes from Common Crawl.
There are a few noteworthy exceptions, such as the New York Times, which does not want its content used to train AI systems. Other popular websites blocking CCbot include shutterstock.com, reuters.com and goodhousekeeping.com.
Limitations. 241 robots.txt files were not identified/inspected as part of this analysis. (That’s why I wrote “at least” in the opening sentence.)
Originality.ai’s analysis. Websites That Have Blocked OpenAI’s GPTBot – 1000 Website Study
Dig deeper. Should you block ChatGPT’s web browser plugin from accessing your website?



